This is the write-up of a talk I gave at PasswordsCon, which runs as a track inside BSides Las Vegas. It was my first time in Vegas and my first talk at a conference that size, so if the recording has me talking slightly too fast, that is why.
The short version: attackers are starting to throw passwords at login systems that were never meant to work, and that breaks an assumption a lot of defensive tooling is quietly built on.
What a synthetic password is
A synthetic password is a credential that was generated, not leaked and not guessed. It has never appeared in a breach because nobody ever used it. You make it at scale with a script or a model, shaped to look like the kind of password a person would actually choose.
That last part is the point. These are not the 25 character blobs a password manager spits out that look like a bomb went off in the alphabet. They look human. Something like:
Blaire#3863
Elle@2265
jazz!light116
chess&flint152
None of those have ever been typed into anything. They look real enough, and “real enough” is the whole problem.
They are not trying to log in
The instinct is to treat a flood of login attempts as brute force, where the attacker is hoping one of the guesses lands. Synthetic passwords are not really that. The odds of any single generated string matching a real account are tiny, and the attacker knows it. Logging in is not the goal.
The goal is everything that happens around the login attempt:
- Flood the SOC and the SIEM so real credential stuffing hides in the noise.
- Defeat breach matching, because none of these passwords are in any breach corpus.
- Burn analyst time on high volume, high entropy inputs that go nowhere.
In the operational cases that started me down this path, defenders were seeing login traffic that looked like the entire world was trying to get in at once, with passwords that all looked plausible and none of which were known-bad. That is the tell, and it is also the trap.
Making them is trivial
I want to be honest about how low the barrier is. The first generator I wrote was a pile of if-statements I put together quickly with help from ChatGPT. It is a proof of concept, not clever, and I could clearly do better with real effort. It did not matter. You feed it words and numbers, pets, names, drinks, whatever, and it recombines them with separators and digits into human-shaped strings.
I generated 10 million of them and not one was a repeat. The full generator and the analysis scripts are here:
github.com/taffy210/synthetic-passwords-botnet
The experiment
I wanted to put numbers behind the idea rather than just assert it. So I took two corpora and scored both against a breach set of about 10 million known passwords.
- A real corpus: roughly 1 million passwords pulled from recent stealer logs.
- A synthetic corpus: 10 million passwords from my generator.
For each password I computed a per-character Shannon entropy, bucketed it by length and rough pattern, and checked whether it appeared in the breach set. The results are the part worth keeping.
| Real (stealer logs) | Synthetic | |
|---|---|---|
| Passwords analysed | 1,011,844 | 10,000,000 |
| Found in breach corpus | 98.66% | 0.0002% (18 total) |
| Average entropy (per char) | 2.91 | 3.27 |
98.66% of the real passwords were already in the breach set. People reuse, and they reuse heavily, which is depressing but not surprising. Out of 10 million synthetic passwords, 18 collided with the breach set. Effectively zero, and the 18 are just birthday-paradox coincidences on common formats.
Someone in the room pushed on exactly this, asking whether it is statistically possible for almost none of 10 million to show up. It is, and that is the finding. The breach corpus is a list of passwords humans have actually used. Synthetic passwords are novel by construction, so they sail straight past it.
They even look right by length
If length were a giveaway, this would be easy. It is not. Real passwords cluster around 8 to 10 characters; the synthetic set sits a little longer, around 9 to 14, well inside the range a human password lives in.
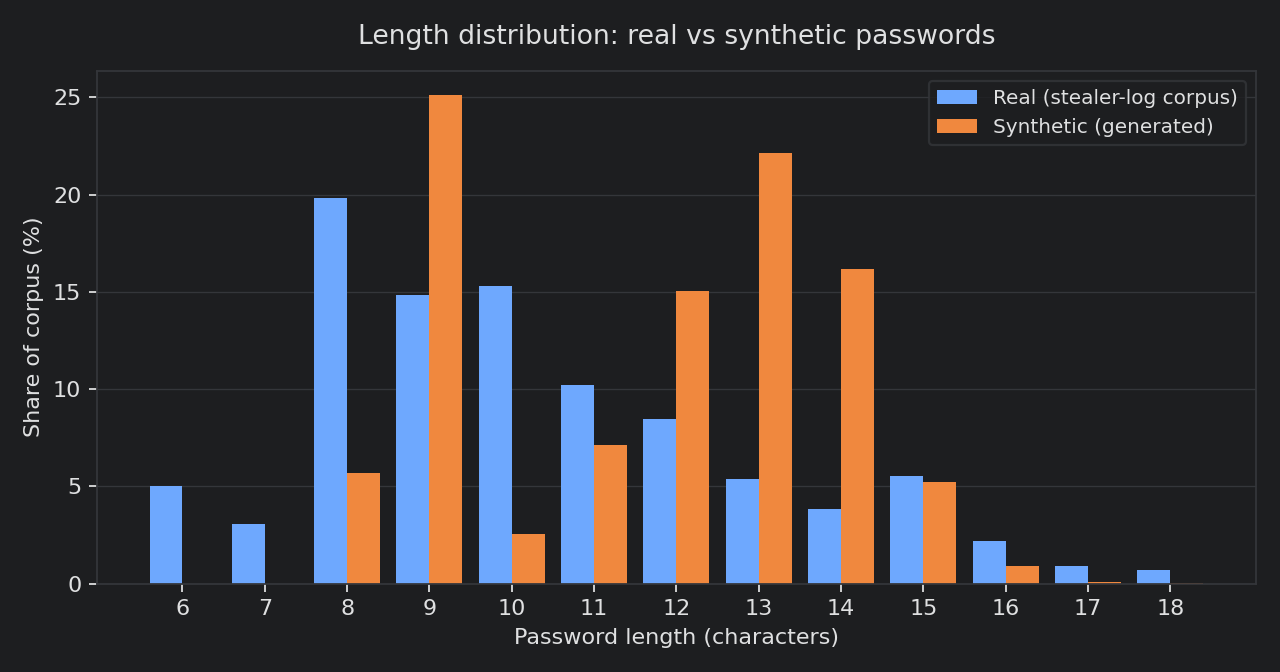
The shapes are not identical, but a synthetic password is not going to stand out in a login stream because it was 41 characters long. It looks like something a person would pick.
Why this breaks defenses
The reason this matters is that a lot of controls lean on the same assumption: if a password has never been seen in a breach, it is probably not part of an attack. Synthetic passwords turn that assumption into an exploit.
- Breach correlation goes blind. Tools that gate on “have I seen this password leak before”, whether that is Have I Been Pwned, a stealer-log feed, or a commercial repository, return a clean result for every synthetic input. Zero match gets read as low threat, and the attempts get waved through.
- Honeywords get harder to trigger. If every attempt is unique and high entropy, decoy credentials and honey accounts are less likely to be tripped, because nothing looks like a targeted guess.
- Behavioral signal gets diluted. When each attempt comes from a different session or IP, with a different plausible password, there is no obvious anchor to pivot on. Not the password, not the source, not the format.
None of these tools are broken. They are answering the question they were designed to answer. The attacker just changed the question.
A detection angle the data handed me
One thing jumped out of the numbers that I did not expect. The synthetic passwords had a tight entropy band, roughly 2.0 to 3.9 per character, while the real corpus ranged from basically 0 up past 6. Human password sets are messy and wide. A generator, unless you work at it, produces something suspiciously uniform.
That uniformity is itself a signal. Real traffic is lumpy. A stream of login attempts whose entropy and format variance are too consistent, too clean, is worth a second look precisely because real users are not that tidy.
What I think defenders should do
Most of this is not exotic. The frustrating part is how often only one method is in place, usually breach correlation on its own.
- Stop treating “not in a breach” as “safe”. It is one weak signal, not a verdict.
- Add entropy scoring and format-variance monitoring, and watch for sudden surges of high-variance inputs.
- Use session and device fingerprinting so the password is not the only thing you are judging.
- Watch for attempts that fail too cleanly. A real person who gets it wrong tries something close to the original next,
passwordthenpassword1. A jump to something completely unrelated every time looks more like a machine.
The bigger shift is from identity-based detection to intent-based detection. Instead of asking only “is this credential known-bad”, ask “does this attempt behave like a human trying to get into their own account”. That is a question a model could reasonably be trained to help with, flagging sessions whose patterns are not human in the same way a CAPTCHA tries to.
Honest caveats
I would rather state the limits than have someone find them for me. The generator is a first pass. Per-character Shannon entropy is a crude measure and not the same as guessing resistance. The breach corpus and the stealer-log corpus overlap by their nature, which is part of why the real match rate is so high. And yes, my conference graph was lopsided enough that the room thought I had lost a fight with PowerPoint. The cleaned-up version is above.
None of that changes the core point. Synthetic passwords are cheap, scalable, and invisible to controls that assume novelty equals safety.
Closing
Synthetic passwords are not on the fringe. Botnets generate them, attack scripts ship them, and they cost almost nothing to produce. The attacker does not care whether the password works, and often does not want it to. The job it is doing is masking and distracting, and it does that job well.
The talk was mostly an awareness piece, because most of the fixes are things this audience already considers obvious. The gap is that obvious and implemented are not the same thing.
Recording is above. Code and data are on GitHub.